Title: Untitled
Creator Lifespan: 1914 - 2002
Creator Nationality: Czech
Creator Gender: male
Creator Death Place: Prague
Creator Birth Place: Protivín
Date: 1980 - 1990
author: Jiří Kolář
Type: collage
《图解密码技术》,这本书个人觉得是很好的基础入门书籍,生动形象的阐述密码学的基本框架和部分技术细节。本篇主要讲解哈希函数和消息认证码
哈希函数
在现代数字世界中,数据安全性和完整性是至关重要的。为了保护数据免受篡改和泄露,密码学中使用了一种称为哈希函数的强大工具
哈希函数,又称单向散列函数(One-way Hash Function),它将任意长度的输入数据转换为固定长度的输出,称为哈希值或散列值或消息摘要或者指纹
单向散列函数具有以下特性:
单向性
对于给定的输入,很容易计算出对应的哈希值,但从哈希值逆推出原始输入是非常困难的,这意味着几乎不可能通过哈希值还原原始数据
固定长度输出
无论输入数据的长度是多少,单向散列函数始终生成固定长度的哈希值,常见的单向散列函数输出长度为128位、256位或更长
碰撞抗性
单向散列函数应该具有良好的碰撞抗性,即很难找到两个不同的输入产生相同的哈希值,理想情况下,即使输入稍微有所改变,其哈希值也应该完全不同
敏感性
输入数据的微小变化应该显著改变其哈希值,这被称为输入的敏感性,这使得单向散列函数在校验数据完整性时非常有用
MD5
MD5是一种单向散列函数,它将任意长度的输入数据转换为128位的哈希值,由Ronald Rivest于1991年开发,是MD2、MD4的改进版本
MD5的哈希计算过程
数据填充
将输入数据进行填充,使其长度满足特定要求:
1)原始数据长度:假设原始数据的长度为L bit。
2)填充位:在原始数据的末尾添加一个”1” bit,后面紧跟着若干个”0” bit,直到满足填充后的数据长度(包括原始数据和填充位)模512等于448,换句话说,填充后的数据长度是512的整数倍减64 bit
3)长度表示:在填充后的数据末尾添加一个64 bit的二进制表示的原始数据长度L(注意,这个长度表示是指原始数据的长度,而不是填充后的数据长度)
通过这种填充方式,保证了数据填充后的长度总是512的整数倍,并且包含了原始数据的长度信息。这是为了满足MD5压缩函数对数据的要求,并且确保在计算哈希值时不会丢失原始数据的信息
初始状态设置
设置初始哈希值,包括四个32位的寄存器:
1
2
3
4
A寄存器初始值:0x67452301
B寄存器初始值:0xEFCDAB89
C寄存器初始值:0x98BADCFE
D寄存器初始值:0x10325476
这些初始值是通过对32位的十六进制常量进行设定而得到的,它们为算法提供了初始的上下文和基础状态,用于后续的消息块处理和哈希计算
在MD5算法的每次迭代中,这四个寄存器的值会根据消息块的处理结果进行更新,即压缩函数的输出将被用于更新寄存器的值,以便在下一次迭代中使用
消息分组处理
将输入数据分成512位的消息块,对每个消息块进行处理
如果填充后的数据长度超过512位,将会有多个消息块,每个消息块包含512位的数据,可以看作是一个固定长度的数据块
如果填充后的数据长度小于等于512位,那么只有一个消息块,其长度等于填充后的数据长度
通过将输入数据分割成多个消息块并对每个消息块进行处理,MD5算法能够处理任意长度的输入数据,并生成一个固定长度的哈希值
压缩函数
对每个消息块应用压缩函数,该函数通过执行一系列位操作、逻辑函数和非线性函数来混合数据
更新哈希值
根据压缩函数的输出更新寄存器的值,具体步骤为:
1)初始化轮常量:每轮迭代都有一个专门的轮常量,用于该轮中的运算。这些轮常量是固定的,并且在MD5算法的规范中定义为特定的常量
2)分配寄存器:压缩函数使用四个32位的寄存器(A、B、C、D)来保存中间结果和状态
3)迭代运算:压缩函数对每个消息块进行多轮的迭代运算。每轮迭代包括16个操作步骤,其中每个步骤应用了不同的非线性函数和位操作
4)子块处理:每个消息块被分为16个32位的子块(每个子块占4个字节)。在每轮迭代中,压缩函数对这些子块进行处理,使用特定的非线性函数和位操作来转换数据
5)更新寄存器:在每次迭代的最后,压缩函数将当前轮的结果与寄存器中的值进行相加,并将结果更新到相应的寄存器中。这样,寄存器中的值会随着每轮迭代而更新,用于下一轮的计算
6)最终结果:经过所有轮的迭代后,压缩函数的最终结果将存储在寄存器中。这些寄存器的值将用于下一个消息块的处理,或者作为MD5算法的最终输出
输出
将最终的四个寄存器值串联起来形成128位的哈希值
MD5的应用场景
数据完整性校验
通过计算数据的哈希值,可以验证数据是否被篡改过。如果接收到的数据的哈希值与预期的哈希值不一致,就说明数据可能被篡改了
密码存储
MD5常用于存储密码的哈希值。将密码经过MD5处理后,将得到的哈希值存储在数据库中,而不是直接存储原始密码。这样即使数据库泄露,攻击者也很难还原出原始密码
文件校验
MD5可以用于校验文件的完整性,比如下载文件时可以计算文件的哈希值与官方提供的哈希值进行比对,以确保文件没有被损坏或篡改
安全性
MD5 已经被证实能被碰撞攻击,碰撞攻击是指找到两个不同的输入,但它们产生相同的MD5哈希值,这会导致MD5的安全性被破坏
因此,对于需要高度安全性的应用,不推荐使用MD5
SHA-1/SHA-2
SHA-1(Secure Hash Algorithm 1)
SHA-1是一种32位哈希算法,广泛应用于数字签名和数据完整性验证等领域。然而,由于SHA-1存在碰撞攻击的弱点,它已经被认为是不安全的,并逐渐被更强大的哈希算法所取代。
SHA-256(Secure Hash Algorithm 256)
SHA-256是SHA-2(SHA-2家族包括SHA-224、SHA-256、SHA-384和SHA-512)中的一种。它生成256位(32字节)的哈希值,并提供了更高的安全性和抗碰撞能力
SHA-256广泛应用于密码学、数字证书、区块链等领域,被认为是目前最常用的哈希算法之一
SHA-384(Secure Hash Algorithm 384)
SHA-384是SHA-2家族中的一员,生成384位(48字节)的哈希值。SHA-384提供了更大的哈希值长度和更高的安全性,适用于需要更高级别的数据完整性和安全性的场景
SHA-512(Secure Hash Algorithm 512)
SHA-512也是SHA-2家族中的一种,生成512位(64字节)的哈希值。与SHA-256和SHA-384相比,SHA-512提供了更大的哈希值长度和更高的安全性
这些算法都是基于Merkle-Damgard结构,并具有相似的设计原理和迭代过程;它们都将输入数据分块处理,并通过一系列的位操作、非线性函数和轮常量来转换数据;这些算法的输出具有固定长度,分别为256位、384位和512位。
注意,随着时间的推移,SHA-2系列算法的安全性也在逐渐受到挑战,出于更高的安全需求,一些应用正在逐渐转向使用更强大的哈希算法,如SHA-3系列算法
SHA-3
SHA-3(Secure Hash Algorithm 3)是由美国国家标准与技术研究院(NIST)于2015年发布的一种哈希算法,它是作为SHA-2算法的补充而设计的,旨在提供更高的安全性和更好的性能
SHA-3算法采用了Keccak的置换与扩展函数结构。与之前的SHA算法不同,Keccak是基于海绵结构(sponge construction)的设计,海绵结构充分利用了置换函数和扩展函数的优势,提供了更高的安全性和性能
SHA-3在设计时考虑了之前哈希算法所发现的一些安全漏洞和攻击方法,并采用了不同的设计原理和算法结构,因此,从理论上讲,SHA-3系列算法在安全性上具有一定的优势
接下来我们详细介绍一下Keccak,它既是SHA-3的基础,也是以太坊中的重要密码学算法(以太坊中使用的是Keccak256)
Keccak256
NIST接受原始的Keccak256设计后,更改了Padding的格式, 以太坊坚持使用了原始的方案,因为这一更改存在争议,导致了正式的SHA3实现和原始的Keccak不兼容
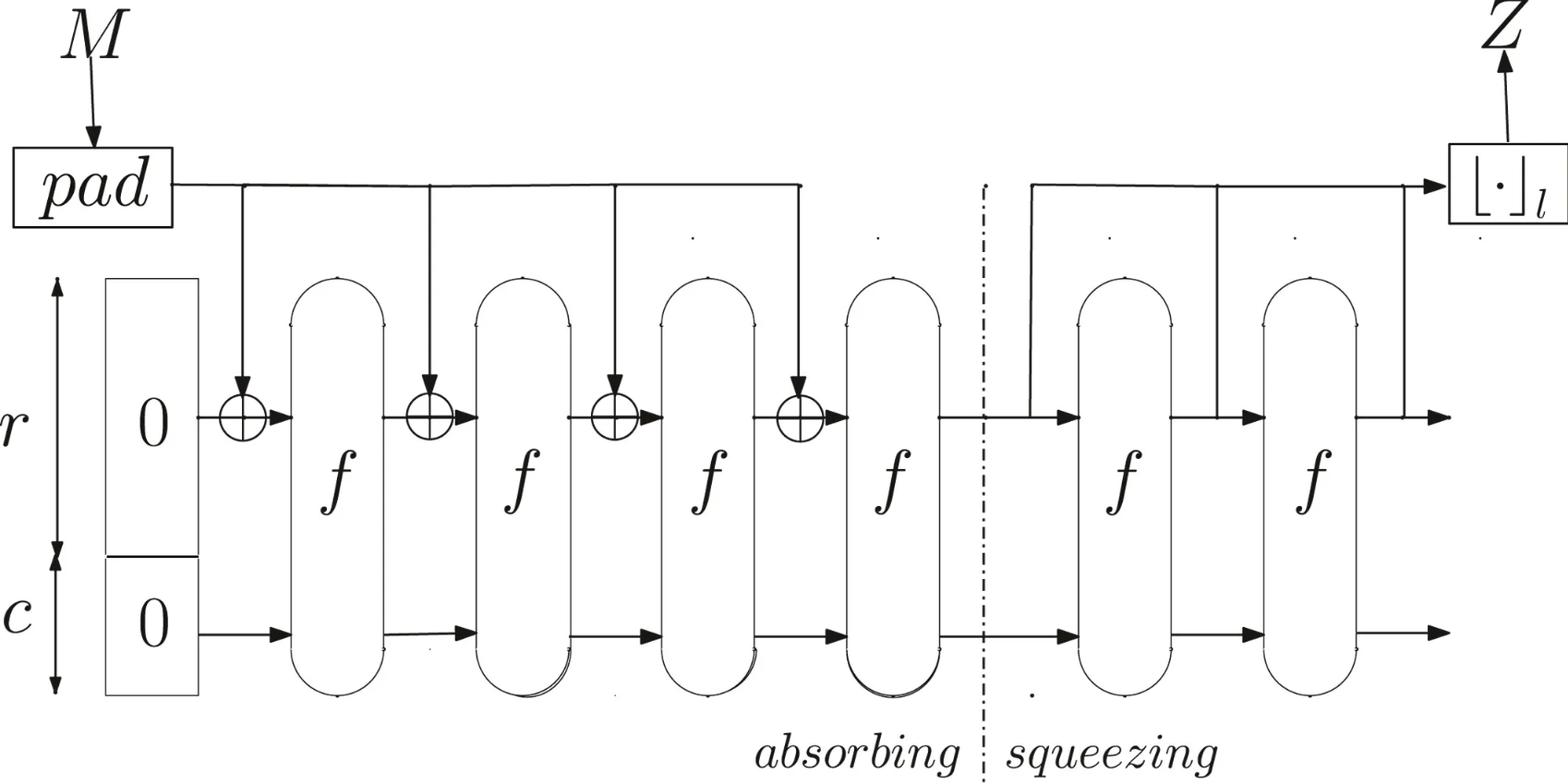
Keccak的核心结构由五个主要部分组成:置换函数(permutation function)、状态(state)、填充(padding)、吸收阶段(absorbing phase)和挤出阶段(squeezing phase):
置换函数
Keccak的置换函数是Keccak-f,它通过一系列的置换运算来混淆和扩散输入数据,其结构是基于固定大小的状态数组和一组轮函数:
-
状态矩阵是一个五维的布尔矩阵,用于存储算法中的中间数据
-
轮函数(round function)是Keccak-f函数的基本操作,它通过应用一系列置换运算来处理状态数组
Keccak-f函数的运算过程如下:
-
初始化:将输入数据与状态矩阵进行异或运算
-
轮函数应用:重复应用轮函数若干次,每一轮函数包括以下五个步骤:
-
θ 阶段:通过线性变换来增强数据的混淆性
-
ρ 阶段:对状态数组进行旋转操作
-
π 阶段:对状态数组中的元素进行重排列
-
χ 阶段:通过非线性变换来增强数据的扩散性
-
ι 阶段:对状态数组的某个位置进行异或运算,引入常数值以增加算法的非线性性
-
-
输出:将最终的状态数组输出作为结果
状态
状态是Keccak算法中的内部状态,它由一个五维的状态数组组成。在算法的运行过程中,状态会不断地被更新和修改
通常来说,Keccak的状态是一个5×5×W的布尔矩阵,其中W表示每个状态元素的位数(常见的W值为1,也就是每个状态元素只占据一个比特)
状态矩阵的每个元素被称为一个状态元素,表示为a[x, y, z],其中x、y、z分别代表状态元素在立方体中的坐标,每个状态元素可以存储一个比特,也可以是多个比特(根据W的值而定)
填充
填充是为了适应不同长度的输入数据而添加的额外位数。填充过程是Keccak算法中的预处理步骤之一,确保输入数据的位数满足算法要求
填充规则如下:
首先,将输入数据划分为固定长度的块。每个块的长度取决于Keccak算法所使用的哈希函数类型,如SHA-3-224、SHA-3-256等
然后,对于每个块,添加一个额外的比特,该比特的值为1
最后,添加填充比特,直到达到特定的填充规则。填充规则取决于Keccak算法所使用的哈希函数类型
吸收阶段
吸收阶段是Keccak算法中的主要处理阶段。它通过将输入数据与状态进行异或运算,将数据吸收到状态中,Keccak的吸收阶段包括以下步骤:
将输入数据分成固定长度的块。每个块的长度取决于Keccak算法所使用的哈希函数类型,如SHA-3-224、SHA-3-256等
对于每个块,将其与状态矩阵进行异或操作,异或运算的结果会将输入数据的位混入到状态矩阵的对应位置上
重复上述步骤,直到所有的输入数据块都被吸收到状态矩阵中
挤出阶段
Keccak算法的挤出阶段是指在吸收阶段之后,从状态矩阵中提取出哈希值的过程。在挤出阶段,Keccak算法将状态矩阵中的数据进行处理和压缩,并生成最终的哈希值作为输出
具体而言,Keccak的挤出阶段包括以下步骤:
-
定义输出长度:确定所需的哈希值长度,如SHA-3-224、SHA-3-256等
-
重复以下步骤,直到生成所需长度的哈希值:
1)将状态矩阵的一部分(也称为“切片”)输出作为哈希值的一部分。这个切片通常是状态矩阵的容量部分,具体取决于哈希函数的类型
2)对状态矩阵进行一系列的置换运算,以更新状态矩阵的内容
3)重复上述步骤,直到生成的哈希值达到所需的长度
在挤出阶段,Keccak算法通过对状态矩阵进行一系列的变换和压缩操作,逐渐生成哈希值的各个部分
Keccak 应用
安全哈希算法:Keccak作为SHA-3算法的基础,可以用于生成安全的哈希值。它广泛应用于数字证书、数据完整性验证、密码学协议等领域
伪随机数生成器:Keccak的结构和性质使其适用于构建高质量的伪随机数生成器(PRNG)
密码学协议:Keccak算法在密码学协议中被用作消息认证码(MAC)和密码哈希函数的基础
区块链技术:Keccak被广泛应用于区块链技术中,例如以太坊(Ethereum)就采用了Keccak算法作为其加密算法,用于计算区块的哈希值
消息认证码
消息认证码(Message Authentication Code,MAC)是一种密钥相关的哈希函数,用于验证消息的完整性和真实性。它接受一个密钥和消息作为输入,并生成一个固定长度的认证标签,这个标签可以用于验证接收到的消息是否被篡改或伪造。
原理与过程
MAC 的计算基于密钥和消息,通常使用特定的哈希函数或加密算法来生成认证标签,常见的 MAC 算法包括 HMAC(Hash-based Message Authentication Code)和 CMAC(Cipher-based Message Authentication Code)等
具体而言,使用 MAC 的过程如下:
1)发送方选择一个密钥
2)使用密钥和消息作为输入,通过特定的算法计算 MAC
3)将生成的 MAC 附加到发送的消息中
4)接收方接收到消息和附加的 MAC
5)接收方使用相同的密钥和相同的算法对接收到的消息计算 MAC
6)接收方将计算得到的 MAC 与附加的 MAC 进行比较
7)如果两个 MAC 匹配,则消息被认为是完整和真实的;否则,消息可能被篡改或伪造